The Tetris design system:
Write code, delete most of it, write more code, delete more of it, repeat until you have a towering abomination, ship to client.
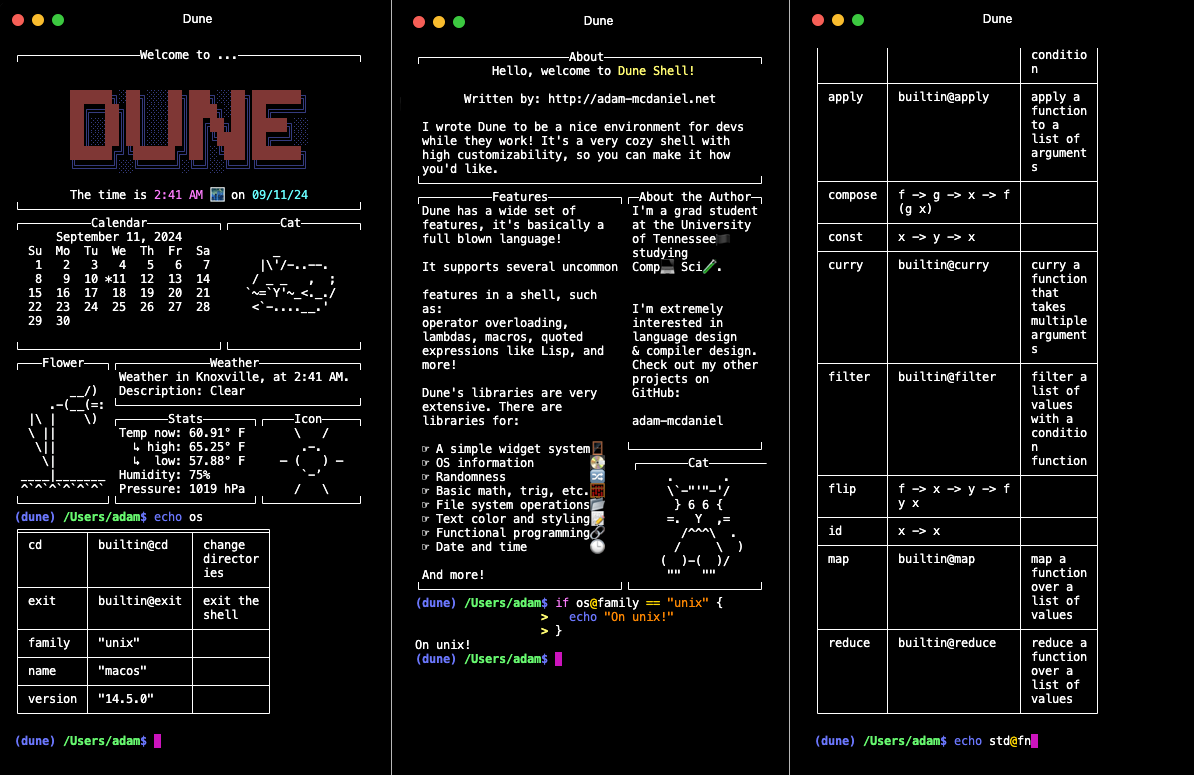
Dune is a shell designed for powerful scripting. Think of it as an unholy combination of
bashand Lisp.You can do all the normal shell operations like piping, file redirection, and running programs. But, you also have access to a standard library and functional programming abstractions for various programming and sysadmin tasks!
The Tetris design system:
Write code, delete most of it, write more code, delete more of it, repeat until you have a towering abomination, ship to client.
But is it rewritten in Rust?
C++

“I’ve got 10 years of googling experience”.
“Sorry, we only accept candidates with 12 years of googling experience”.
Author's comment on lobste.rs:
Yes it’s embeddable. There’s a C ABI compatible API similar to what lua provides.
C++’s mascot is an obese sick rat with a missing foot*, because it has 1000+ line compiler errors (the stress makes you overeat and damages your immune system) and footguns.
EDIT: Source (I didn't make up the C++ part)


I could understand method = associated function whose first parameter is named self, so it can be called like self.foo(…). This would mean functions like Vec::new aren’t methods. But the author’s requirement also excludes functions that take generic arguments like Extend::extend.
However, even the above definition gives old terminology new meaning. In traditionally OOP languages, all functions in a class are considered methods, those only callable from an instance are “instance methods”, while the others are “static methods”. So translating OOP terminology into Rust, all associated functions are still considered methods, and those with/without method call syntax are instance/static methods.
Unfortunately I think that some people misuse “method” to only refer to “instance method”, even in the OOP languages, so to be 100% unambiguous the terms have to be:
impl block.self (even if it takes Self under a different name, like Box::leak).self, so it can be called like self.foo(…).Java the language, in human form.
I find writing the parser by hand (recursive descent) to be easiest. Sometimes I use a lexer generator, or if there isn’t a good one (idk for Scheme), write the lexer by hand as well. Define a few helper functions and macros to remove most of the boilerplate (you really benefit from Scheme here), and you almost end up writing the rules out directly.
Yes, you need to manually implement choice and figure out what/when to lookahead. Yes, the final parser won’t be as readable as a BNF specification. But I find writing a hand-rolled parser generator for most grammars, even with the manual choice and lookahead, is surprisingly easy and fast.
The problem with parser generators is that, when they work they work well, but when they don’t work (fail to generate, the generated parser tries to parse the wrong node, the generated parser is very inefficient) it can be really hard to figure out why. A hand-rolled parser is much easier to debug, so when your grammar inevitably has problems, it ends up taking less time in total to go from spec to working hand-rolled vs. spec to working parser-generator-generated.
The hand-rolled rules may look something like (with user-defined macros and functions define-parse, parse, peek, next, and some simple rules like con-id and name-id as individual tokens):
; pattern ::= [ con-id ] factor "begin" expr-list "end"
(define-parse pattern
(mk-pattern
(if (con-id? (peek)) (next))
(parse factor)
(do (parse “begin”) (parse expr-list) (parse “end”))))
; factor ::= name-id
; | symbol-literal
; | long-name-id
; | numeric-literal
; | text-literal
; | list-literal
; | function-lambda
; | tacit-arg
; | '(' expr ')'
(define-parse factor
(case (peek)
[name-id? (if (= “.” (peek2)) (mk-long-name-id …) (next))]
[literal? (next)]
…))
Since you’re using Scheme, you can almost certainly optimize the above to reduce even more boilerplate.
Regarding LLMs: if you start to write the parser with the EBNF comments above each rule like above, you can paste the EBNF in and Copilot will generate rules for you. Alternatively, you can feed a couple EBNF/code examples to ChatGPT and ask it to generate more.
In both cases the AI will probably make mistakes on tricky cases, but that’s practically inevitable. An LLM implemented in an error-proof code synthesis engine would be a breakthrough; and while there are techniques like fine-tuning, I suspect they wouldn’t improve the accuracy much, and certainly would amount to more effort in total (in fact most LLM “applications” are just a custom prompt on plain ChatGPT or another baseline model).

Brand X